Rows: 582
Columns: 16
$ name <chr> "Fortnight (feat. Post Malone)", "The Tortured Poets …
$ album <chr> "THE TORTURED POETS DEPARTMENT: THE ANTHOLOGY", "THE …
$ release_date <chr> "2024-04-19", "2024-04-19", "2024-04-19", "2024-04-19…
$ track_number <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16…
$ uri <chr> "spotify:track:6dODwocEuGzHAavXqTbwHv", "spotify:trac…
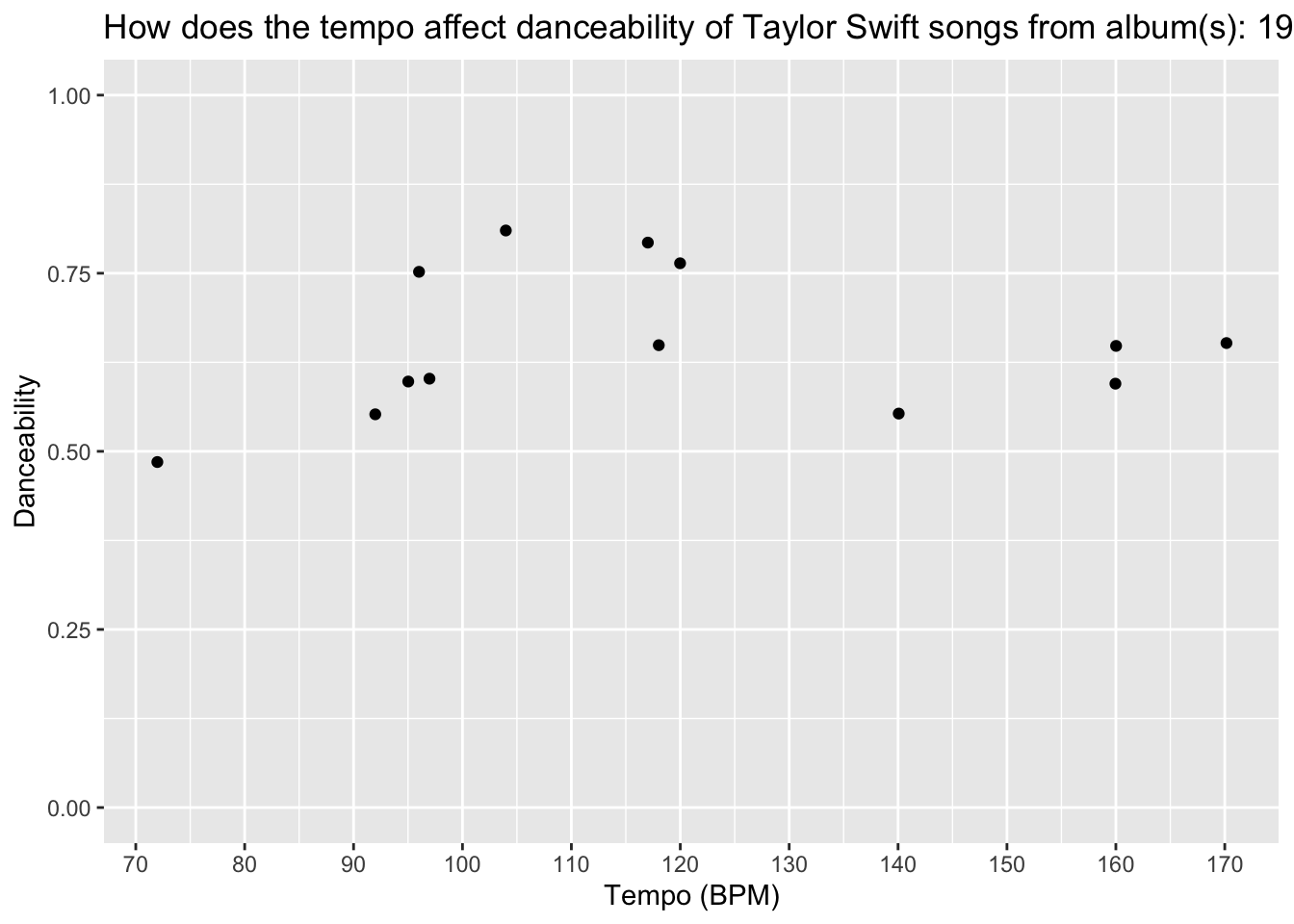
$ acousticness <dbl> 0.5020, 0.0483, 0.1370, 0.5600, 0.7300, 0.3840, 0.624…
$ danceability <dbl> 0.504, 0.604, 0.596, 0.541, 0.423, 0.521, 0.330, 0.53…
$ energy <dbl> 0.386, 0.428, 0.563, 0.366, 0.533, 0.720, 0.483, 0.57…
$ instrumentalness <dbl> 1.53e-05, 0.00e+00, 0.00e+00, 1.00e-06, 2.64e-03, 0.0…
$ liveness <dbl> 0.0961, 0.1260, 0.3020, 0.0946, 0.0816, 0.1350, 0.111…
$ loudness <dbl> -10.976, -8.441, -7.362, -10.412, -11.388, -7.684, -9…
$ speechiness <dbl> 0.0308, 0.0255, 0.0269, 0.0748, 0.3220, 0.1040, 0.039…
$ tempo <dbl> 192.004, 110.259, 97.073, 159.707, 160.218, 79.943, 8…
$ valence <dbl> 0.281, 0.292, 0.481, 0.168, 0.248, 0.438, 0.340, 0.39…
$ popularity <int> 82, 79, 80, 82, 80, 81, 78, 79, 82, 81, 77, 80, 82, 8…
$ duration_min <dbl> 3.816083, 4.884133, 3.396683, 4.353800, 4.382900, 5.6…