Now let’s it’s time to really SEE our data. We will explore a tidyverse package called ggplot2, though we just say “ggplot” without the 2. It is a series of functions that allows you to crate any chart you want - just like how you can combine different ingredients to make different meals. Instead of just picking from pre-made chart types like pie or bar charts, you build your visualization in layers by choosing what data to show, how to represent it (like with points, lines, or bars), and how to arrange everything on the canvas. Think of it like LEGO bricks - you can combine simple pieces (like marks, scales, and coordinates) in different ways to create exactly the chart you need to tell your data’s story.”
The package ggplot2 is quite extensive, allowing us to create a number of visualizations with tremendous flexibility and customization. We will just touch the surface of what it can do, but there are other great resources to learn more about what it can do:
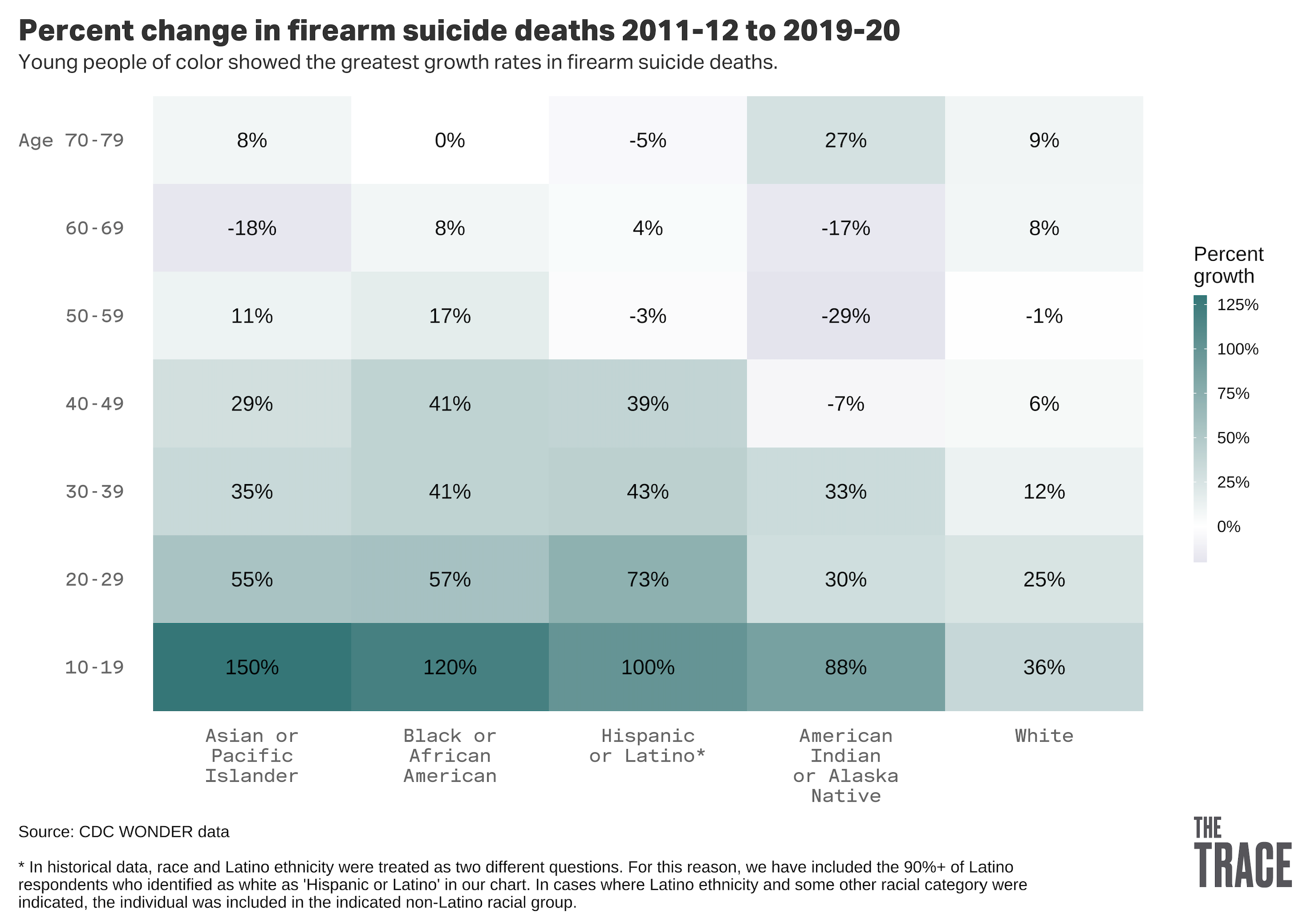
Here are some example charts to show how different they can be ..
Setup
At the end of our last lesson we “Rendered” our page into HTML so you can share your analysis with others. Each Quarto document needs to run independently to render, so each notebook must have the code to load the libraries and data it needs.
That’s what this next chunk is. We are loading some libraries and importing our data again. Make sure you run this chunk!
Trying to directly chart 2 million rows of data isn’t very effective, so we usually summarize our data using the techniques from our last lesson.
Summarizing our top 5
In this case, we will take the five most popular names from 2023, and plot them as a bar chart. We’ll start by getting our data ready.
This next code block starts with the babynames data, filters it to just 2023, and the “slices” it to get the five highest values in the times_given column. It is then sorted by sex. The result of all that was saved into a new object called top_5_data, which is what we’ll plot.
top_5_data <- babynames |>filter(year ==2023) |>slice_max(times_given, n =5) |>arrange(sex)top_5_data
Building a chart in layers
Usually when we build a chart, we would keep adding our layers into the SAME code chunk, rerunning the code with each addition to make sure the changes work the way we want. In this exercise, we are creating new code chunks so you can see the difference between each layer as we add it.
Also, with this first chart we are going to do a LOT of modifications, more than you might need just so see your data. But the idea is to show you the kinds of things that you can change, and how.
The canvas
First, let’s create a blank canvas
top_5_data |>ggplot()
This doesn’t show us much, but be patient.
Aesthetics
Beyond our data, the next thing our chart needs is which data to use to build it’s x and y axis. In our case, we want our names to go along the bottom (the x axis) and the number of times that name was given along the y axis.
Each time we want to pull from our data to use in our chart, we have to reference it through a function called aes(), which is short for aesthetics. It’s called “aesthetic” because it deals with how things look and how we perceive them - just like how art is about the aesthetics of color, shape, and form.
top_5_data |>ggplot(aes(x = name, y = times_given))
This adds the axis names, but it doesn’t show anything on the chart yet because there are soooo many different ways we could do that. We need to specify what shape to use.
Geoms
To paint our data onto our canvas, we need to describe the shape or “geometry” that we want to see. There are many choices, and the functions always start with geom_. The geoms determine what kind of chart will get added to our canvas.
Here we will add a geom to make a column chart. When we add a layer onto our chart, we use the + sign at the end of a line, then the new layer.
top_5_data |>ggplot(aes(x = name, y = times_given)) +geom_col()
OK, we are getting somewhere, but this is not really how we want this to look.
Reorder bars
First, let’s order the bars by the times_given. We’ve also reorganized our code a little bit because with more options, it gets hard to read. By breaking it up into multiple lines, it’s easier to see what’s going on.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)), # edits to reorder the barsy = times_given )) +geom_col()
That’s getting a bit better, but that color is hideous!
Setting a color
In R, we can use a selection of named colors, or any hex value.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given )) +geom_col(fill ="cadetblue", alpha = .8) # arguments set colors and transparency
Looking better, but I don’t love the y-axis. Let’s add commas to the tick mark labels.
Formatting the y-axis
We can use a function scale_y_continuous to make adjustments to this y-axes, adding commas to the numbers using the label argument and a function from the scales package called label_comma().
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given )) +geom_col(fill ="cadetblue", alpha = .8) +scale_y_continuous(labels =label_comma()) # edits y numbers to add commas
If that seems a bit esoteric, you are right. I did NOT know that from the top of my head, I had to look it up. You can change anything you want on a ggplot chart if you know the proper function, but there are a ton of them. I’ll often consult the ggplot2 cheat sheet, the ggplot book or the ggplot2tor apps to find function names.
Adding labels and a title
Now let’s get rid of that ugly background, those axis labels, and add a title to our chart.
We’ve added a function called labs() that allows us to add and modify much of the text on a chart. We’ve added a title and subtitle to our chart, and we’ve set our x and y axis labels to be blank by setting them to an empty string.
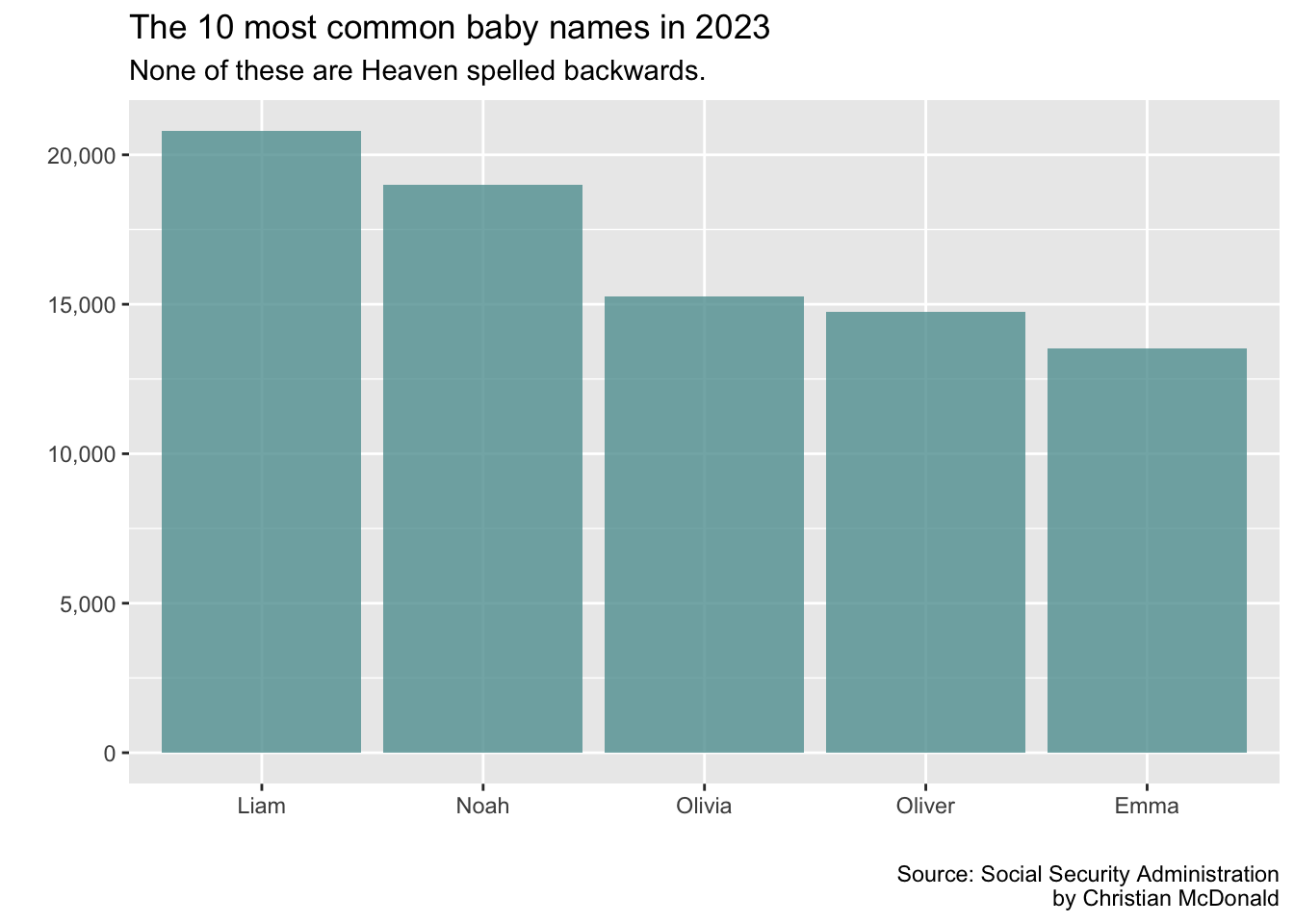
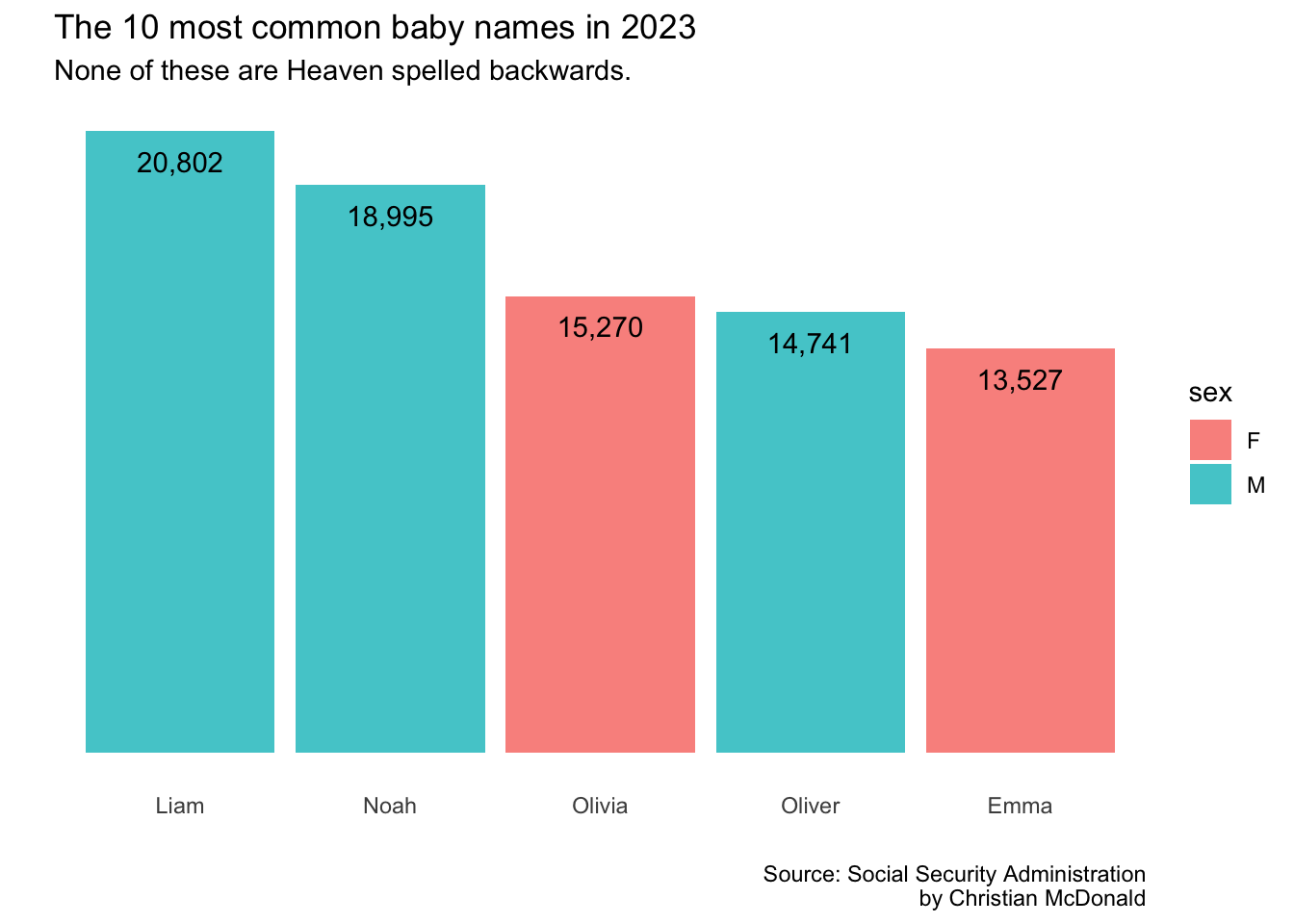
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given )) +geom_col(fill ="cadetblue", alpha = .8) +scale_y_continuous(labels =label_comma()) +# labs add or adjusts text itemslabs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald" )
Adding geoms
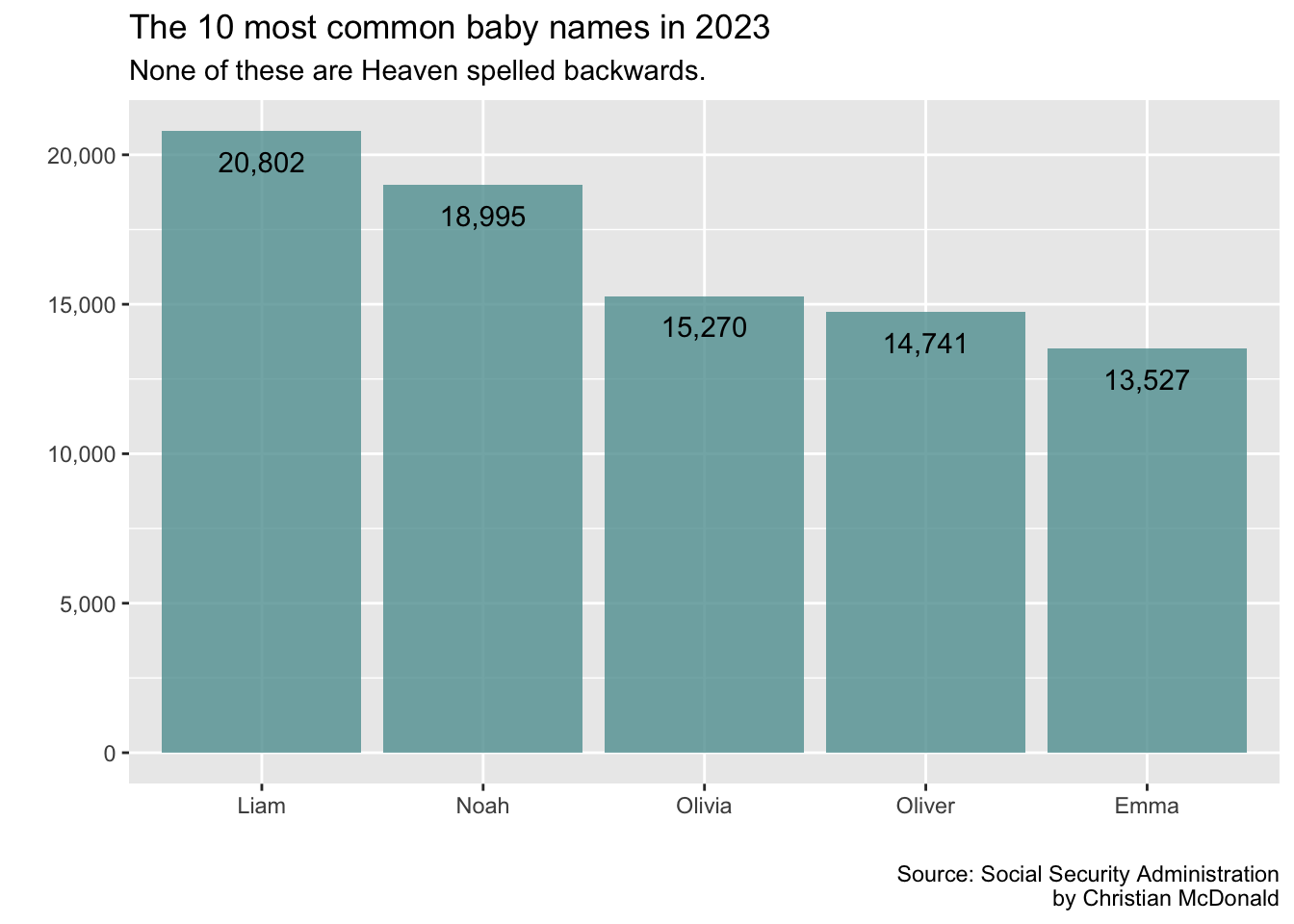
We can add text to our chart using the geom_text() function. In that function We’ve added a label argument so it plots the times_given values onto the chart as text. Note that because we are pulling from our data to get the times_given, we have to use an aes() function to get it on our chart. It’s placing the text right where the data would plot, so at the end of the existing bar on the chart.
But we also added the vjust argument that tells the function to adjust the vertical position of the text up or down. Since this value of “2” isn’t coming from the data, this argument is outside the aes() function.
Try adjusting the vjust = 2 value to another number like “3” or “-1” to see what it does. Then put it back. ;-).
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given)) +geom_col(fill ="cadetblue", alpha = .8) +scale_y_continuous(labels =label_comma()) +labs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald" ) +geom_text(aes(label =comma(times_given)), vjust =2) # plots the times_given values as text
This is looking pretty good, but now we have labels both on the axis and the bars, and we don’t need both. We also could clean this up by removing the background.
Themes
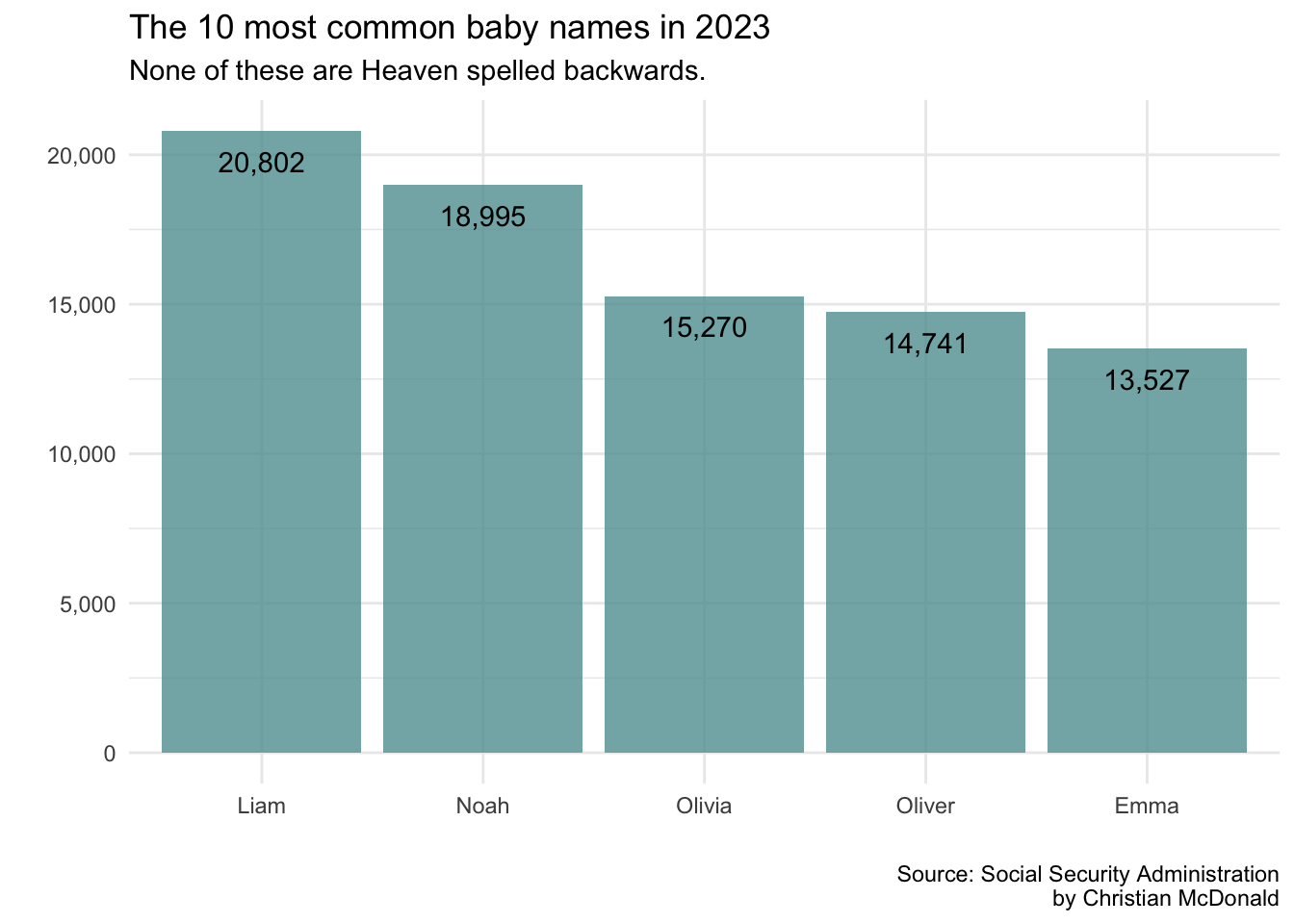
Themes are basically a combination of pre-set functions that control the look of a chart. Ggplot has several built-in themes and the one we add below is theme_minmal, which removes the background grid and other elements.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given)) +geom_col(fill ="cadetblue", alpha = .8) +scale_y_continuous(labels =label_comma()) +labs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald" ) +geom_text(aes(label =comma(times_given)), vjust =2) +theme_minimal() # changes the theme
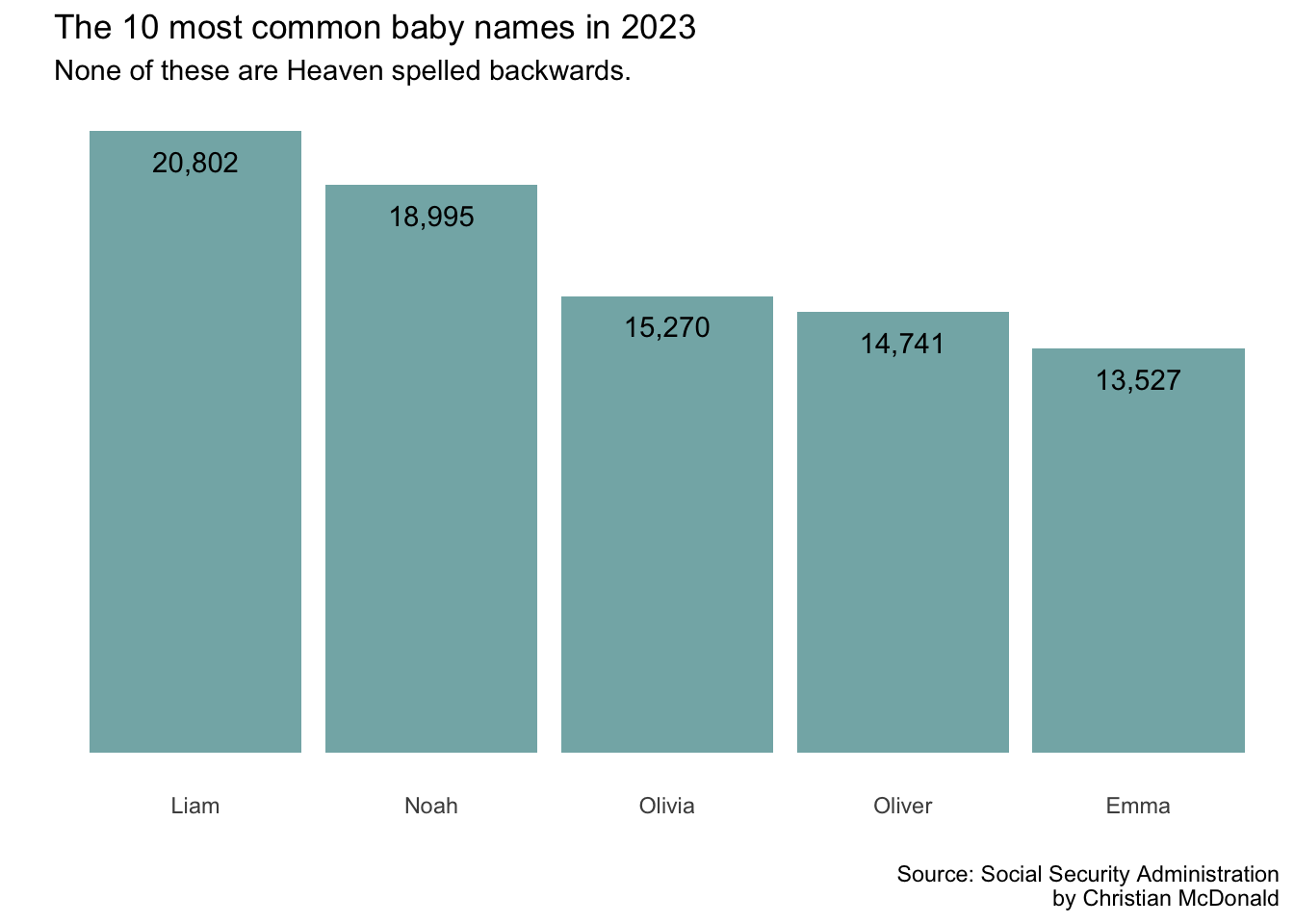
And that indeed helped us a bit, but I’d like to get rid of the gridlines an axis measurements. We can do that with the theme() function, but again we have to look up the arguments to know what to set them to. I used this ggplot2tor theme finder to find them.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given)) +geom_col(fill ="cadetblue", alpha = .8) +scale_y_continuous(labels =label_comma()) +labs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald" ) +geom_text(aes(label =comma(times_given)), vjust =2) +theme_minimal() +# the stuff below removes grid lines, etc.theme(axis.text.y =element_blank(),panel.grid.major =element_blank(),panel.grid.minor =element_blank() )
OK, that’s looking pretty good. But what if we want to color.
Manual colors
Some of these are characterized as male names and some as female. What if we want to color code them?
In our global aes() function we can pull from our data to code the bars based on sex. We’ve added fill = sex as noted in comments below.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given,fill = sex # added fill here )) +geom_col(alpha = .8) +scale_y_continuous(labels =label_comma()) +labs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald" ) +geom_text(aes(label =comma(times_given)), vjust =2) +theme_minimal() +theme(axis.text.y =element_blank(),panel.grid.major =element_blank(),panel.grid.minor =element_blank() )
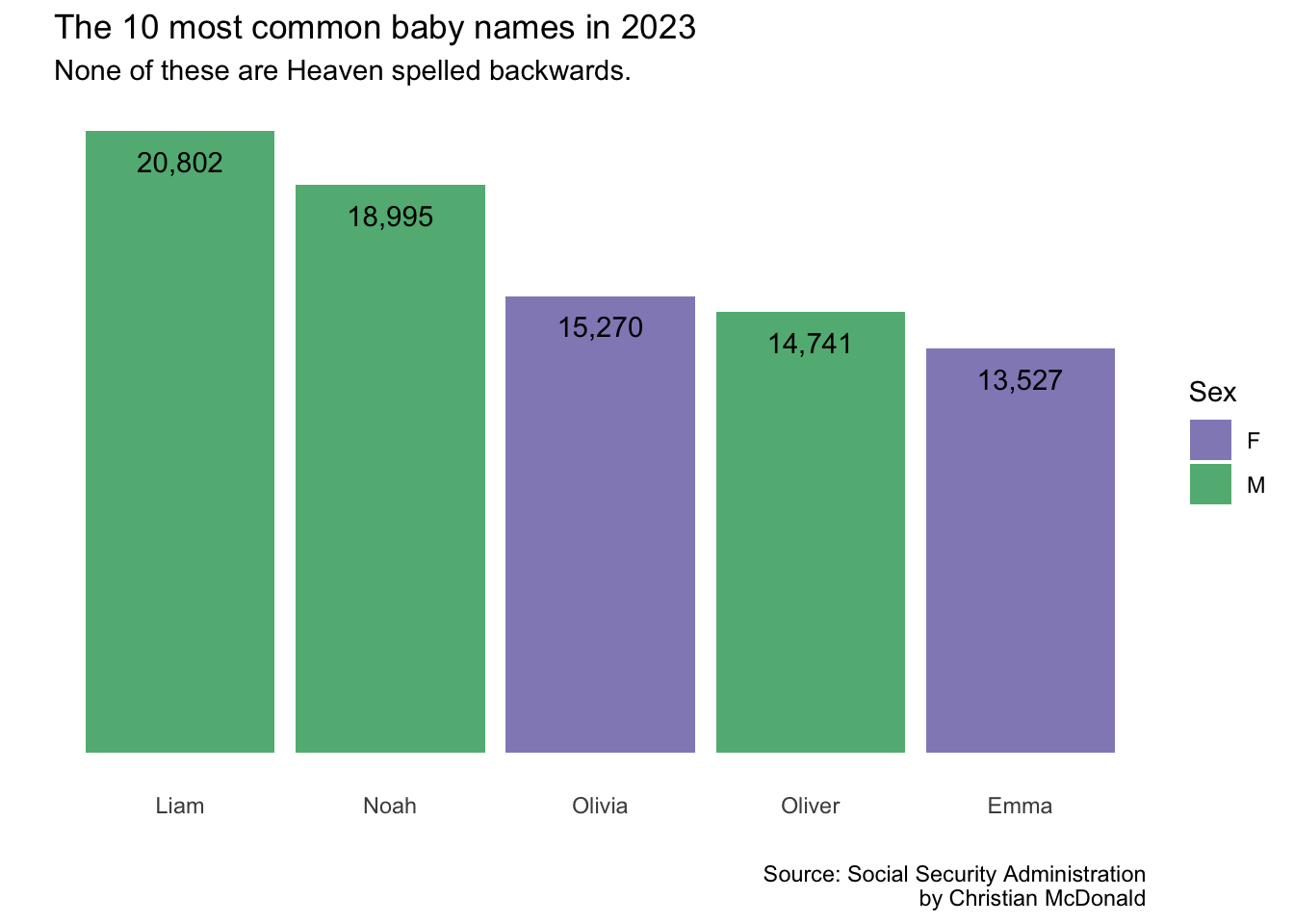
Not bad, but these colors are kinda problematic, let’s pick our own. Again, we might have to do some research to figure out how, searching in ggplot book or the ggplot2tor scale finder
We’re adding a scale_fill_manual() function to set the colors of the bars.
We’re adding an argument in labs() to change/capitalize the title of the legend.
top_5_data |>ggplot(aes(x =reorder(name,desc(times_given)),y = times_given,fill = sex # added fill here )) +geom_col(alpha = .8) +scale_y_continuous(labels =label_comma()) +labs(title ="The 10 most common baby names in 2023",subtitle ="None of these are Heaven spelled backwards.",x ="", y ="",caption ="Source: Social Security Administration\nby Christian McDonald",fill ="Sex"# added to change legend title ) +geom_text(aes(label =comma(times_given)), vjust =2) +theme_minimal() +theme(axis.text.y =element_blank(),panel.grid.major =element_blank(),panel.grid.minor =element_blank() ) +scale_fill_manual(values=c("#756bb1", "#2ca25f")) # changes color of bars
OYO: Make a bar chart
With a buddy, make your own super awesome bar chart. Remember you’ll first have to summarize your data to make it manageable.
If you need an idea, I have one here for you. Below you’ll find code that filters our data to find all the instances of our most popular male name from 2023, “Liam”. You could plot the number of times this name has been given with x as the year and y as the number of times given.
You might also change the name or sex value to get data for a different name.
oyo_col_data <- babynames |>filter(sex =="M", name =="Liam")oyo_col_data
Now that you have data, edit this code to make a column chart:
Start by adding x and y values in the aes() function to the appropriate columns.
Add a geom_col() function to add the columns to the chart.
Add a labs() function for titles, etc.
oyo_col_data |>ggplot()
Line chart
So far, we’ve been plotting one type of thing. But what if we want to see how the popularity of multiple names have changed over time? We can use a line chart to show that.
Prepping the data
We’ll need to figure out what those top names are and build our data set to include them. We’re going to do this in two steps. First we need to find our most popular names and create a list of them to filter with.
We create a new object name because you have to have a bucket before you can fill it.
We start with our babynames data.
We filter it to just the year 2023 and for just females.
We slice the data to get the top 5 names by times_given.
In the second step we use the pull() function to pull out just the names from the data set. We save that, too, because it’s what we’ll use to filter our data.
top_fname_2023 <- babynames |>filter(year ==2023, sex =="F") |>slice_max(times_given, n =5)top_fname_2023
Now that we have a list of names, we’ll use that to filter our original data to include rows just with those names.
Here we create our new data bucket, then fill it …
We start with our original baby names data, but then we filter it to rows where the name is any value in our top_names_2023 list. We also filter for just females because some names could also be given to males, which would muck up everything. (Don’t they always? badumph!)
top_5f_years <- babynames |>filter(name %in% top_fname_2023_list, sex =="F")top_5f_years
Start with canvas
Again, normally we would build this chart step by step in the SAME code chunk, but we will create new ones here so you can see the differences in each step.
We start by setting up our canvas, setting what data we want on the x and y axis.
top_5f_years |>ggplot(aes(x = year, y = prop))
And now we’ll add lines and adjust our code to be more readable. There are a couple of parts to this:
geom_line() is the geom to add lines to the chart.
However if we only add geom_line the chart doesn’t know to split the lines by name. We have to tell it to do that by adding color = name to the aes() function.
We’ve also added the minimal them just to look nicer.
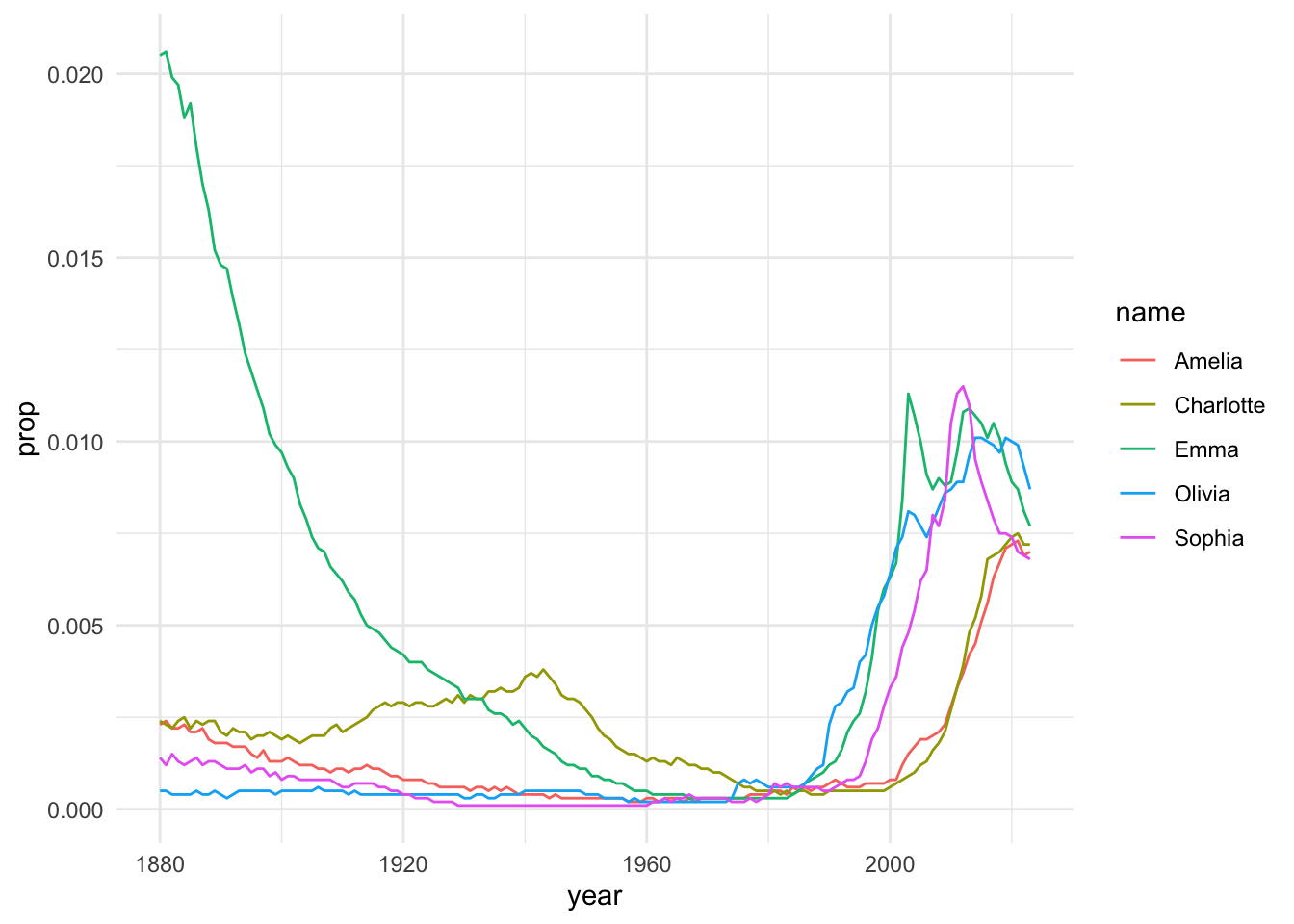
top_5f_years |>ggplot(aes(x = year, y = prop, color = name)) +# color added to separate the linesgeom_line() +# adds the linestheme_minimal() # adjust the theme
Cosmetic adjustments
Now we can make some cosmetic changes to our chart. We’re adding a lot here at once in the interest of time. Again, we would likely reference the ggplot book or ggplot2tor site to find the functions we need to make these changes.
We adjust the y axis to use % instead of fractions
We adjust the frequency of the grid lines on the x axis
In our labs we add basic titles and adjust the axis labels
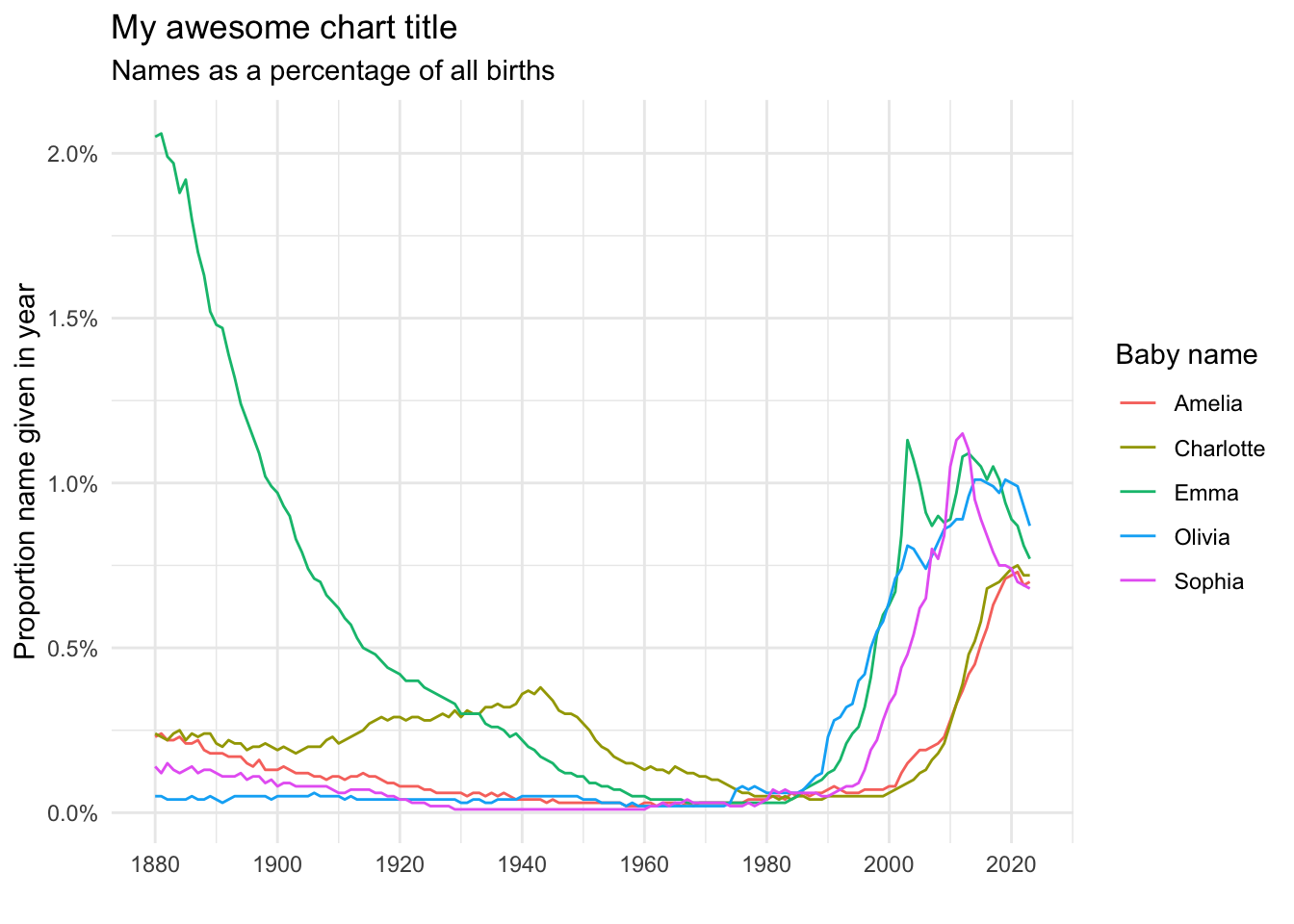
top_5f_years |>ggplot(aes(x = year, y = prop, color = name)) +geom_line() +scale_y_continuous(labels = scales::percent) +# % in y axisscale_x_continuous(breaks =seq(1880,2023,20)) +# adjust x grid linestheme_minimal() +labs(title ="My awesome chart title",subtitle ="Names as a percentage of all births",color ="Baby name",y ="Proportion name given in year", x ="" )
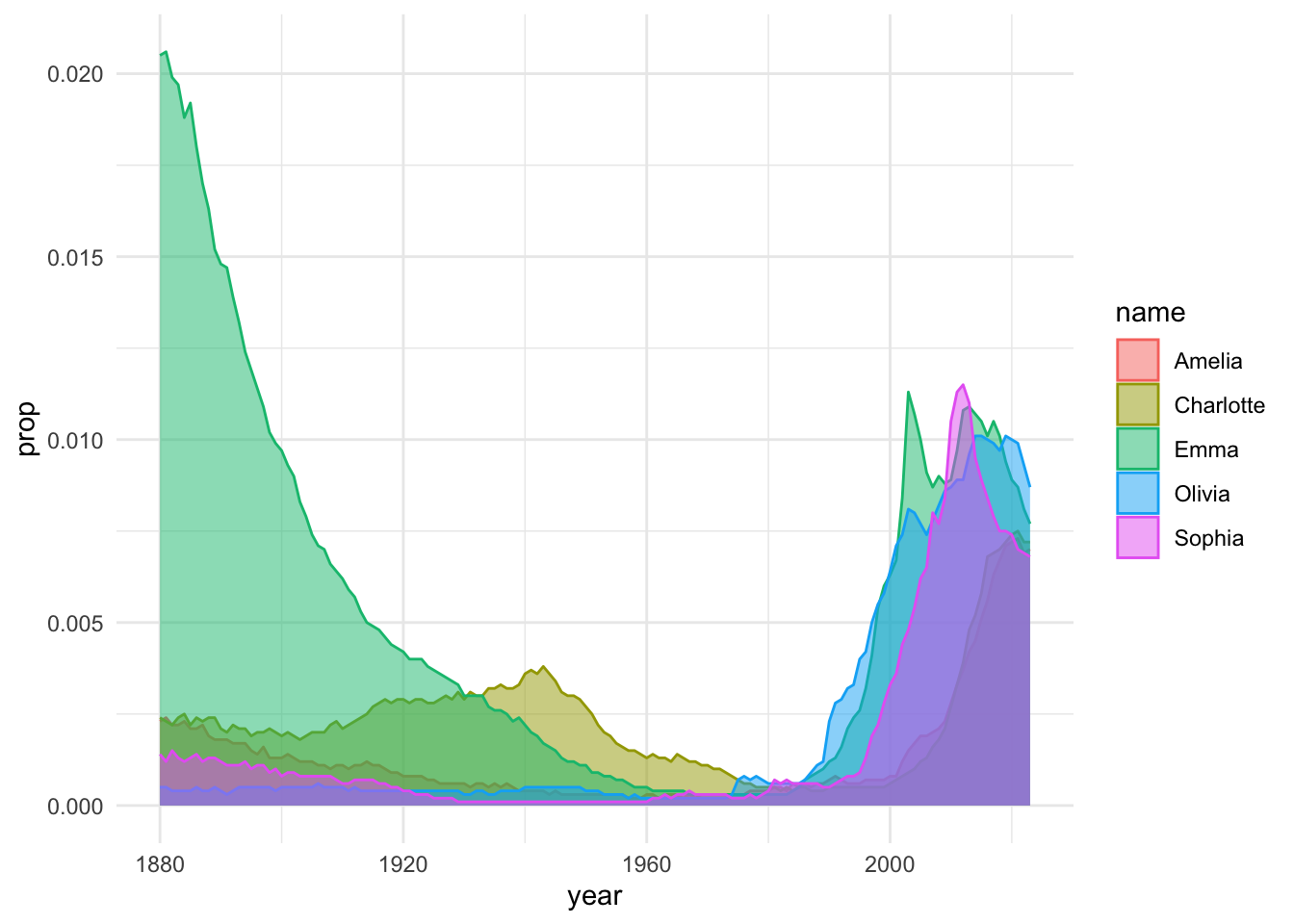
And here’s a quick alternative version of the same chart using geom_density. It might be pretty, but is is easier to read?
top_5f_years |>ggplot(aes(x = year, y = prop, color = name, fill = name)) +geom_density(stat ="identity", alpha = .5) +theme_minimal()
OYO: Make a line chart
With a buddy, make your own super awesome line chart. Remember you’ll first have to summarize your data to make it manageable.
I’ll prep some data for you to track the popularity of the names “James” and “Mary” over time. You can use this data to make a line chart.
james_mary <- babynames |>filter( (name =="James"& sex =="M") | (name =="Mary"& sex =="F") )james_mary
Now plot the prop values for these two names over time.
Faceting
Faceting is a way to break up your data into smaller pieces and plot them separately. This is useful when you have a lot of data and you want to see how different parts of it compare to each other.
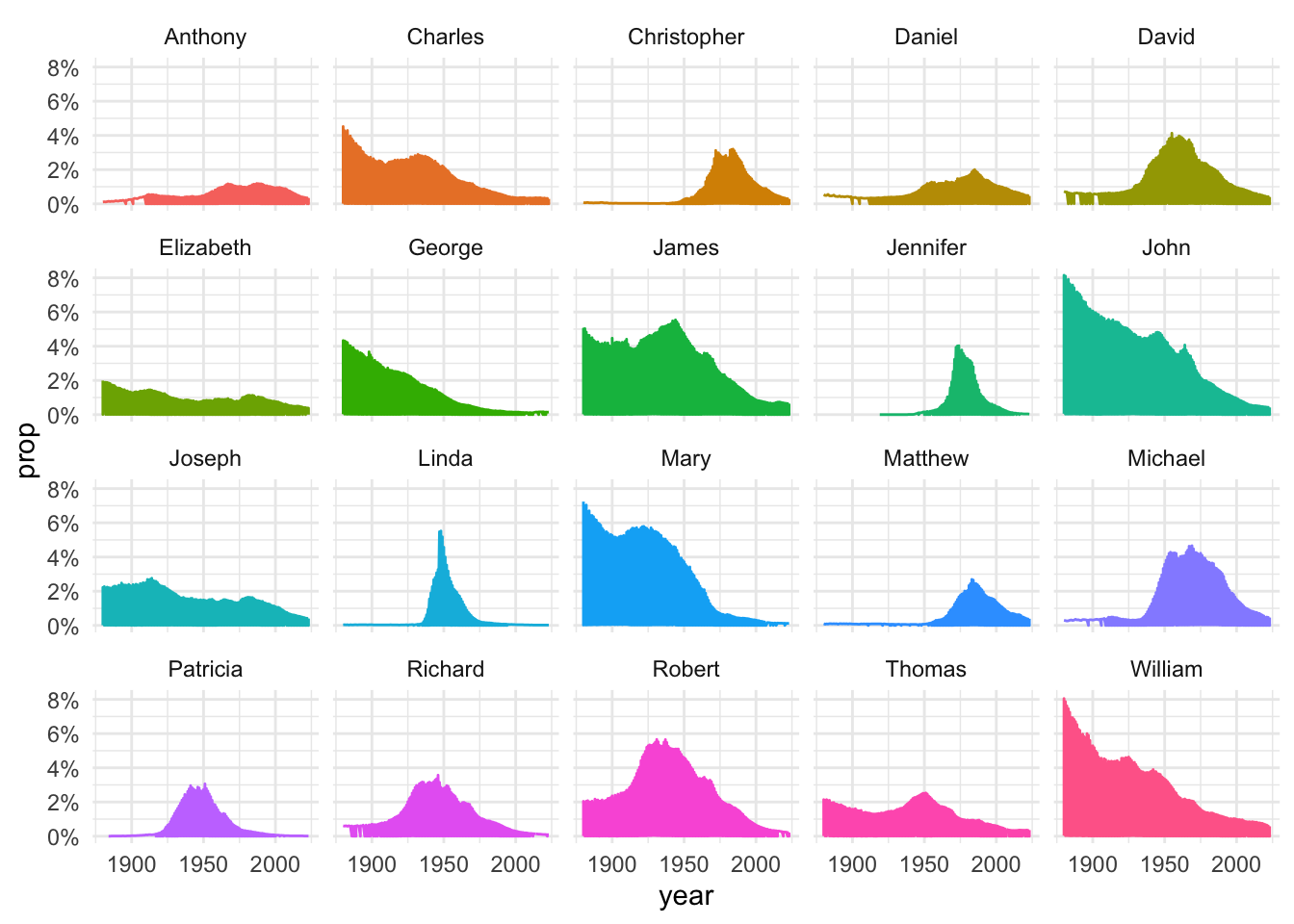
Let’s walk through an example of this by plotting the popularity of the top 20 names over time.
First we need to find those top 20 names. It’s similar to what we did for the top 5 female names so I’m going to skip that explanation here.
And now the chart. We’re going to add a facet_wrap() function to our chart to break it up by name. We also make some other changes to use percentages, change the grid lines to every 50 years, and some other theme changes.
top20_names_data |>ggplot(aes(x = year, y = prop, color = name)) +geom_line() +scale_y_continuous(labels = scales::percent) +scale_x_continuous(breaks =seq(1900,2023,50)) +theme_minimal() +theme(legend.position ="none") +facet_wrap(vars(name), ncol =5) # this is the facet magic
More on your own
What do you want to know about the history of names in America? Let’s figure it out.