Expand this to see code
library(tidyverse)
library(janitor)
library(scales)
library(DT)library(tidyverse)
library(janitor)
library(scales)
library(DT)We’re bringing in:
logs_all <- read_rds("data-processed/01-outdoor-cleaned.rds") # come from 01-outdoor-cleaning
hourly <- read_rds("data-processed/01-station-hourly-protocols.rds")
units <- read_rds("data-processed/01-unit-info-cleaned.rds")We have eight days of data, but we can clip it to a “week” as the last seven seven days of July, 2023. As of July 2025, we are not clipping.
logs <- logs_all
# |> filter(date != "2023-07-24")
logs |> count(date) |> adorn_totals() |> tibble()Here we bring in the unit info and hourly logs.
# getting station from units
logs_expanded <- logs |>
left_join(units, by = join_by(unit == unit_name, region)) |>
# removing some unneeded cols
select(!c(unit_code, type, county, nws))
# joining to get weather info
logs_nws <- logs_expanded |>
left_join(hourly, by = join_by(nws_id == station_id, date == date, hour == hr))
logs_expanded |> filter(str_detect(unit, "Jordan"))Here we find the percentage of records with no NWS data.
match_checks <- logs_nws |>
mutate(match_null = if_else(is.na(name), T, F))
match_checks |>
tabyl(match_null) |>
adorn_pct_formatting()About 15 percent of our hourly logs don’t have a station match. Here TRUE values means there is missing station data.
Let’s take a look at which ones are at issue:
match_checks |>
tabyl(unit, match_null) |>
adorn_percentages() |>
adorn_pct_formatting() |>
adorn_ns() |>
tibble()In some cases we didn’t have a prison close enough. In other cases – like Jordan – we had a station, but there were no recordings for the time period.
Here is a filtered list to more easily see units that have no NWS readings:
no_compare <- match_checks |>
tabyl(unit, match_null) |>
filter(`FALSE` == 0) |>
tibble()
no_compareWe’re going to remove these units going forward, leaving us with 82 units.
no_compare_units <- no_compare |> pull(unit)
logs_nws_compare <- logs_nws |>
filter(!unit %in% no_compare_units)
logs_nws_compare |> count(unit) |> nrow()We don’t have a matching weather station for 11 of the 82 unites. Using visualcrossing we might be able to do a better job finding weather stations, and also to keep a better record of how far away these stations are from the units. We will do this, but later.
ALSO: In May25 work we removed stations with no matching weather station because we were looking at reliability. But if we want instead to look at protocols based on internal records, we shouldn’t remove them.
We must remember these weather stations may be up to 40 miles away from the unit.
Here we find the difference in the prison recorded temp and heat index compared to the nearest station, if we have one. In some cases the diffs are NA because we don’t have a nearby station, or one of the calculating numbers is missing for whatever reason.
We only do this heat index calculation if one of the temperatures if above 80 degrees, because heat indexes get wonky when it is below 80.
logs_diffs <- logs_nws_compare |>
mutate(
tmp_diff = temp - tmp,
hi_diff = case_when(
temp >= 80 | tmp >= 80 ~ hi_wc - hi,
.default = NA
)
)
logs_diffs |> slice_sample(n = 20)Here we look across the dataset at the diff_tmp (unit temperature - weather staiton temperaure).
logs_diffs |>
summarise(
max_tmp_diff = max(tmp_diff, na.rm = T),
avg_tmp_diff = (mean(tmp_diff, na.rm = T) * 100) |> round(1),
med_tmp_diff = median(tmp_diff, na.rm = T)
)Let’s do a quick plot of these to see how the are distributed. i.e., how many rows are within x degrees of the weather station temperature. Note: there are 248 blank rows where we could not determine the difference because of a missing value.
ggplot(logs_diffs, aes(x = tmp_diff)) +
geom_histogram(binwidth = 1, fill = "lightblue", color = "black") +
labs(
title = "Compare temp draft",
subtitle = str_wrap("Each bar is how many unit records are within x degrees of the closest weather station."))Warning: Removed 250 rows containing non-finite outside the scale range
(`stat_bin()`).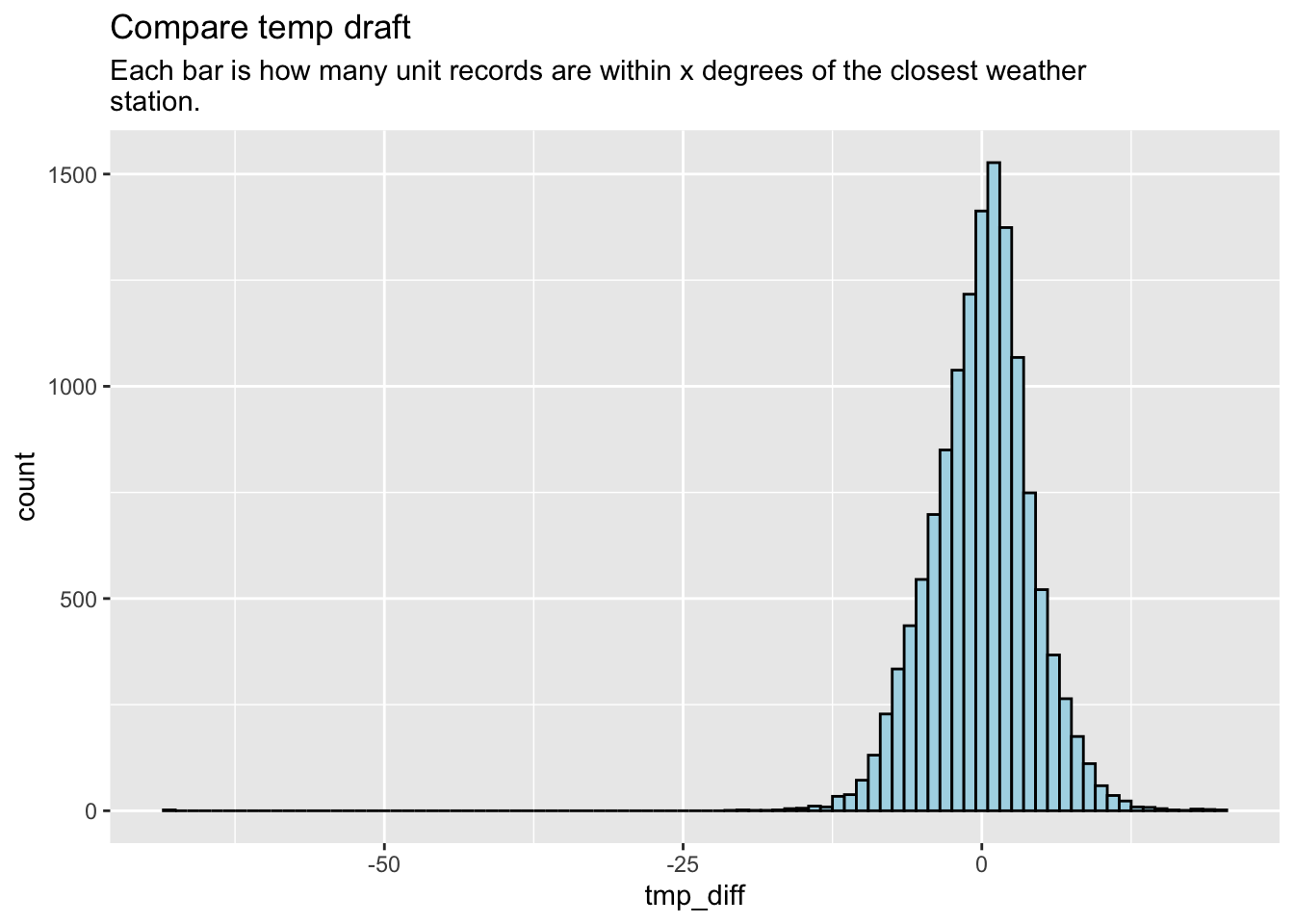
I can see that there are a just a couple of outliers Let’s consider removing those and see the spread mo betta.
There are only five records (out of 11,928) where the temp is 20 or more degrees off.
# the outliers
logs_diffs |>
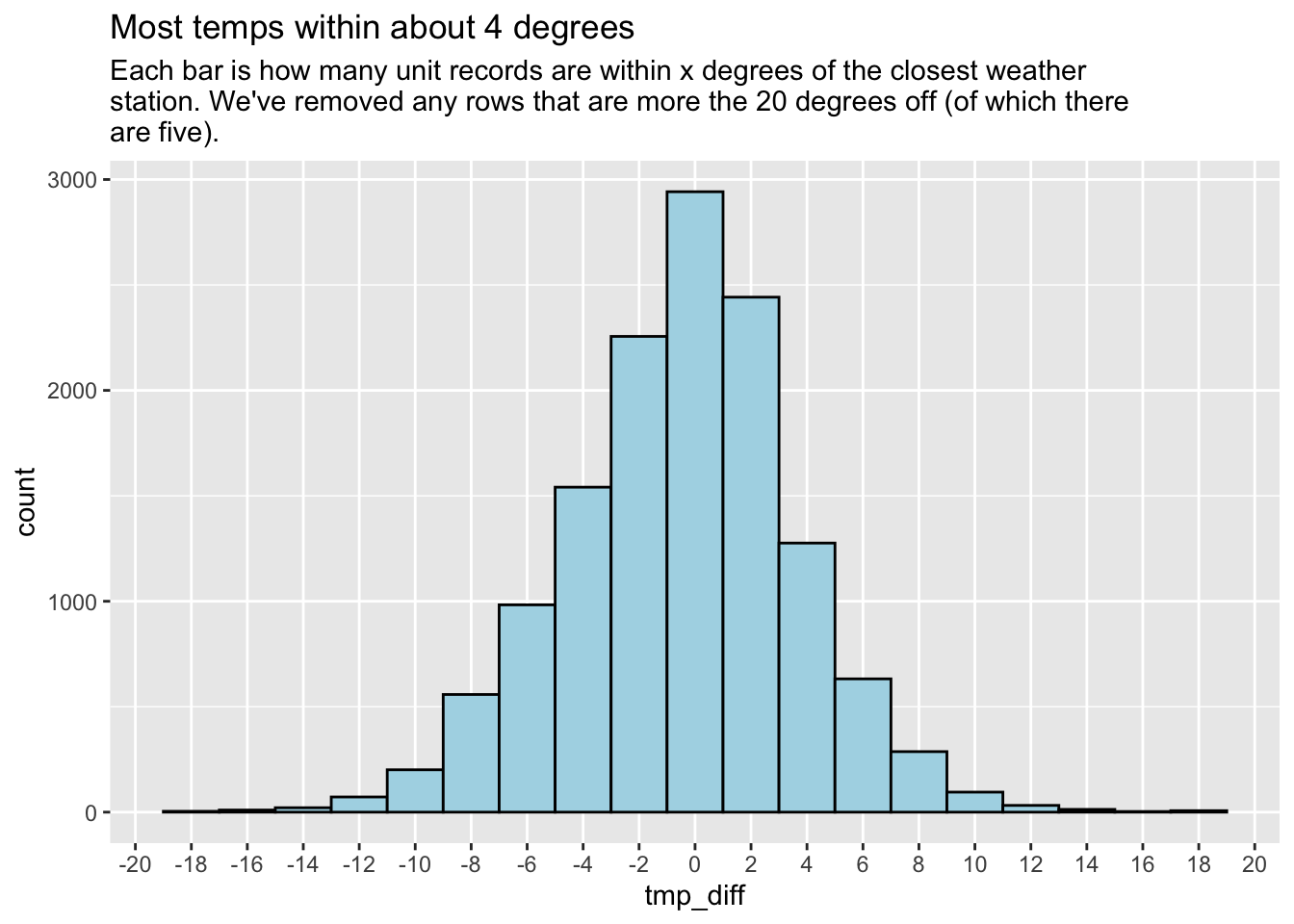
filter(abs(tmp_diff) >= 20)# chart it
logs_diffs |>
filter(abs(tmp_diff) < 20) |>
ggplot() +
aes(x = tmp_diff) +
geom_histogram(binwidth = 2, fill = "lightblue", color = "black") +
scale_x_continuous(breaks = seq(-20, 20, 2)) +
theme(panel.grid.minor.x = element_blank()) +
labs(
title = "Most temps within about 4 degrees",
subtitle = str_wrap("Each bar is how many unit records are within x degrees of the closest weather station. We've removed any rows that are more the 20 degrees off (of which there are five).")
)
How many rows negative vs positive?
logs_diffs |> filter(tmp_diff <= 0) |> nrow() # unit is lower[1] 7053logs_diffs |> filter(tmp_diff > 0) |> nrow() # unit is higher[1] 6329This might be too technical or unneeded, but let’s look at this using the standard deviation. The standard deviation describes how much the values in the dataset typically vary from the mean (average). Like how whacked are they.
# The standard deviation of tmp_diff
# logs_diffs |> summarise(td_sd = sd(tmp_diff, na.rm = T))
tmp_diff_sd <-
logs_diffs |>
filter(abs(tmp_diff) < 20) |>
pull(tmp_diff) |> sd(na.rm = T)
tmp_diff_sd[1] 4.131502# percent outside the sd
logs_diffs |>
filter(abs(tmp_diff) < 20) |>
mutate(
td_sd_out = case_when(
abs(tmp_diff) > tmp_diff_sd ~ T,
.default = F
)
) |>
tabyl(td_sd_out) |>
adorn_pct_formatting()Here about 1/4 of the rows are outside the standard deviation.
This might make more sense to a human: What percentage of the overall records fall within 2 degrees of the nearest weather station. How about within 4 degrees?
We are NOT removing outliers here.
The TRUE value here is the percentage of records within 2 or 4 degrees, respectively. To be clear, within 4 degrees also includes those within 2 degrees.
tmp_diff_2_4 <- logs_diffs |>
# filter(abs(tmp_diff) < 20) |>
filter(!is.na(tmp_diff)) |>
mutate(in_2d = abs(tmp_diff) <= 2,
in_4d = abs(tmp_diff) <= 4)
tmp_diff_2_4 |>
tabyl(in_2d) |>
adorn_pct_formatting()tmp_diff_2_4 |>
tabyl(in_4d) |>
adorn_pct_formatting()Now that seems easier to understand than standard deviation.
Let’s see how this differs by unit.
in_2d_prc is the percentage of records for that unit within 2 degrees the closest weather station. in_4d_prc is the same for within 4 degrees.
tmp_diff_2_4 |>
group_by(unit) |>
summarize(
cnt = n(),
in_2d_true = sum(in_2d == T),
in_2d_prc = ((in_2d_true / cnt) * 100) |> round(1),
in_4d_true = sum(in_4d == T),
in_4d_prc = ((in_4d_true / cnt) * 100) |> round(1)
) |>
# removes the cnt true rows from display
select(unit, ends_with("prc")) |>
arrange(in_2d_prc)Sorted above based on lowest percentage within 2 degrees.
Now, these numbers could really depend on how close the weather station is to the unit. For instance, I’m not happy with the choice of a station at Pearland Regional Airport for the Ramsey unit (maybe 30 miles?). The Angleton/Brazoria airport is closer (13 miles), as is Houston Southwest Airport (14 miles).
We will check all the weather stations and add distance between unit and weather station at a future date.
Let’s do the same for heat index. We’ll skip the standard deviations and just look at the distribution and percentages.
There are about 50 records outside a 20 degree difference that we show here, but remove for the plot.
logs_diffs |>
filter(abs(hi_diff) >= 20)logs_diffs |>
filter(abs(hi_diff) < 20) |>
ggplot() +
aes(x = hi_diff) +
geom_histogram(binwidth = 2, fill = "lightblue", color = "black") +
scale_x_continuous(breaks = seq(-20, 20, 2)) +
theme(panel.grid.minor.x = element_blank())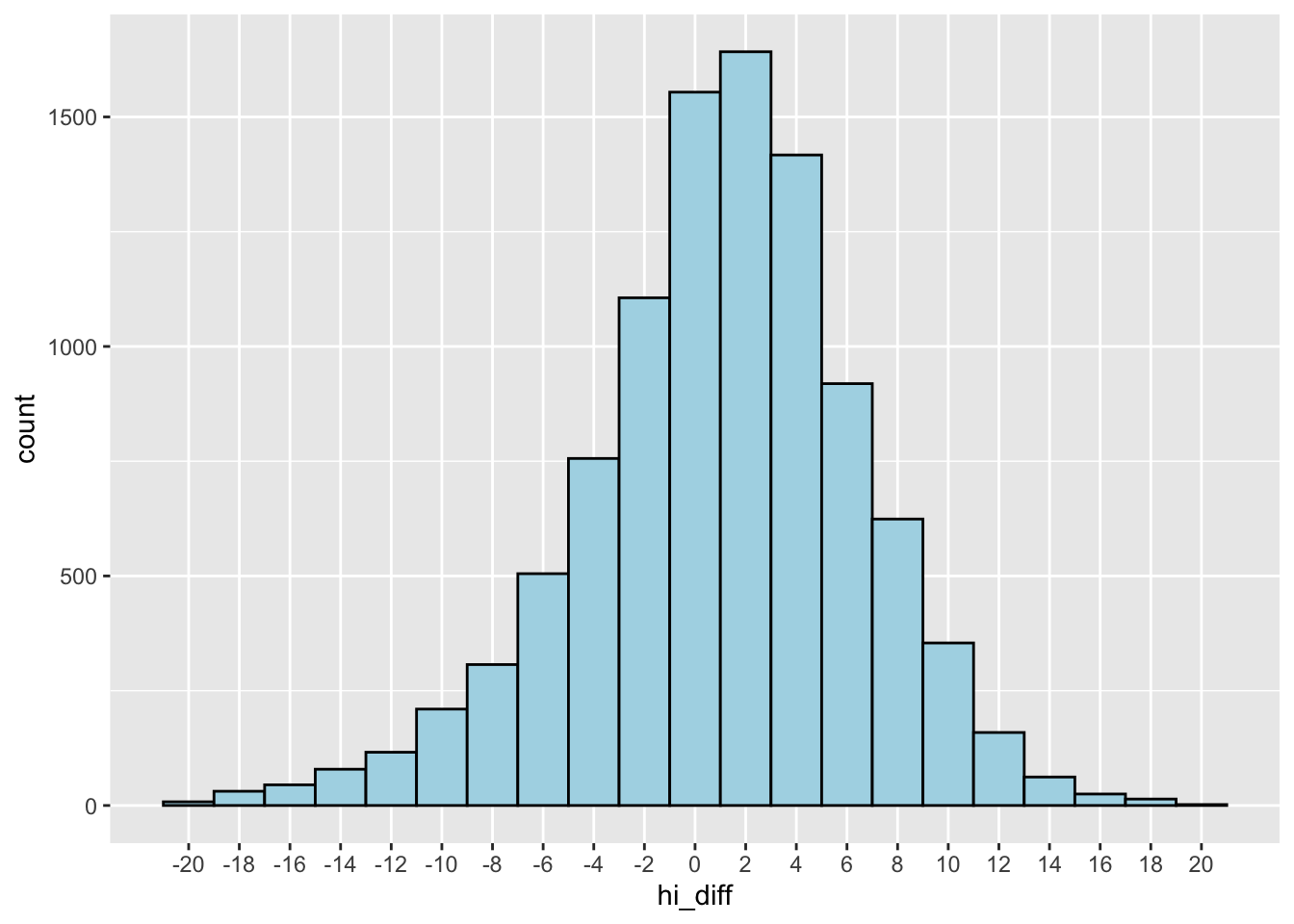
Here we find the percentage of heat index records within 2 or 4 degrees. We are NOT removing outliers here.
TRUE means within 2 or 4 degrees, respectively.
hi_diff_2_4 <- logs_diffs |>
filter(!is.na(hi_diff)) |>
mutate(in_2d = abs(hi_diff) <= 2,
in_4d = abs(hi_diff) <= 4)
hi_diff_2_4 |>
tabyl(in_2d) |>
adorn_pct_formatting()hi_diff_2_4 |>
tabyl(in_4d) |>
adorn_pct_formatting()And now to do that by unit. We have more cases where we don’t have the heat index for both the unit and the weather station, so we include the count of records we are comparing here.
hi_diff_2_4 |>
group_by(unit) |>
summarize(
cnt = n(),
in_2d_true = sum(in_2d == T),
in_2d_prc = ((in_2d_true / cnt) * 100) |> round(1),
in_4d_true = sum(in_4d == T),
in_4d_prc = ((in_4d_true / cnt) * 100) |> round(1)
) |>
# removes the cnt true rows from display
select(unit, cnt, ends_with("prc")) |>
arrange(in_2d_prc)